Select menu: Spread | Manipulate | Unstack
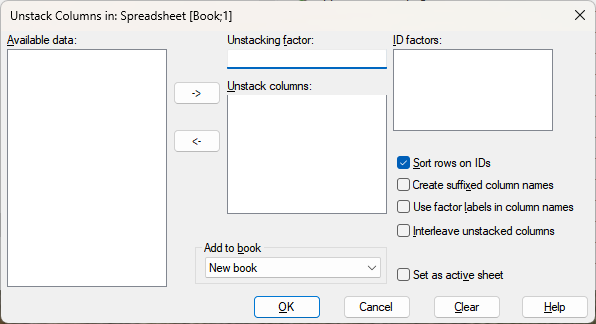
The unstack menu provides a way of splitting a single column up into multiple columns depending on the levels of a classifying factor. All items from rows belonging to the first level will be put in the first unstacked column, the second level into the second columns etc.
Unstacking factor
Specify the name of a factor to use to unstack the columns. The columns will be unstacked using each level of the factor. For example, if the factor has 2 levels then all values corresponding to level 1 will be unstacked in one column and all values corresponding to level 2 will be unstacked into a 2nd column.
ID factors
Specify one or more ID factors to be used to unstack the columns. The combination of ID factors should uniquely identify a row within an unstacking group. The new items are from the different unstacked columns are replaced in rows so that all values in a row had the same ID in the old spreadsheet. A warning is given if there are rows with duplicate IDs. See the example below.
Unstack columns
Specifies the columns that are to be unstacked.
Sort rows on IDs
If selected and an ID factor has been specified, the unstacked columns will be sorted by the levels of the ID factor.
Create suffixed column names
If selected, the names given to the new unstacked columns will be created as a pointer with a numerical suffix (e.g. Column X will be unstacked to X[1], X[2], …).
Use factor labels in column names
If selected and then the labels (or levels if there are no labels for the factor) from the unstacking factor will be used to create the unique column names. Thus if the factor labels were ‘Low’, ‘Medium’ and ‘High’, the names for the new column from an unstacked column would be formed by attaching _Low, _Medium and _High to the original name, rather than the default _1, _2 and _3.
Interleave unstacked columns
If selected then all the stacked columns for the first group will come first, followed by the columns from the second group and so on. Otherwise all the groups for the first column come first, followed by the groups for the second unstacked column and so on. For example, if unstacking columns X, Y and Z by Group with 3 levels, with the interleave option selected the resulting column order will be X_1, Y_1, Z_1, X_2, Y_2, Z_2, X_3, Y_3, Z_3 and if not selected, it will be X_1, X_2, X_3, Y_1, Y_2, Y_3, Z_1, Z_2, Z_3.
Remove excluded rows
If selected and the spreadsheet contains some filtered/restricted data then the columns will be unstacked excluding the rows within the current filter/restriction. By default columns are unstacked ignoring any filter/restriction.
Set as active sheet
Sets the newly created spreadsheet to be the active spreadsheet. See setting an active spreadsheet for more details.
Add to book
This provides a list of books that the new spreadsheet can be added to. The default book that spreadsheets are added to can be specified using the Spreadsheet Options – Books tab menu.
Action buttons
| OK | Create the new unstacked spreadsheet and close the dialog. |
| Cancel | Close the dialog. |
| Clear | Clear all lists and edit boxes. |
Example
The following example shows a spreadsheet with three factor columns Tag, Treat and Date identifying the animals at different dates and a column giving their live weights.
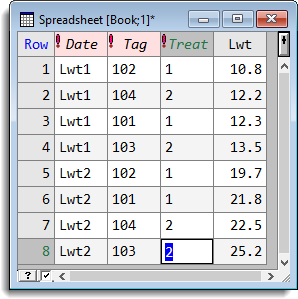
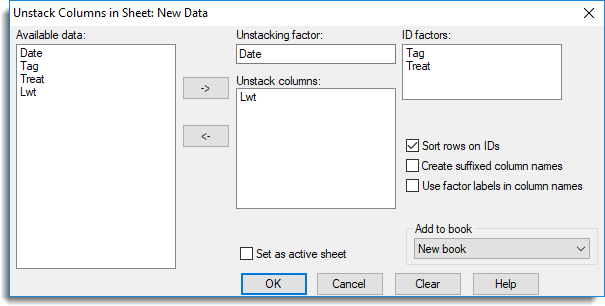
Now using the unstack dialog and specifying that the column Lwt is to be unstacked to be unstacked on Date, the columns Tag and Treat are to be used as ID columns, as shown in the following dialog. This will create two new columns from Lwt, one with all the live weights from the first date and the other from the second date. If the ID columns were not specified, the weights from the same animals would not be put on the same row, as the order the animals occur in is different for both dates.
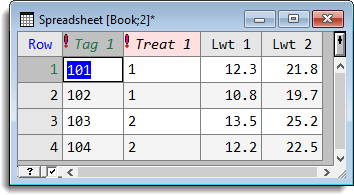
We obtain the resulting spreadsheet shown below. Note the Columns are renamed by appending a _1 on to the end of the existing column ID names to avoid clashes between the two sets of data structures, and the resulting columns from Lwt are labelled with a numerical sequence Lwt_1 and Lwt_2.
See also
- Stack Spreadsheet
- Reshape Data
- Append Data to Spreadsheet
- Merge Spreadsheet
- Expand a Spreadsheet using a Weight Column
- Understanding Factors within a Spreadsheet
- Spreadsheet Manipulate Menu
The UNSTACK procedure provides this functionality within the command language.