Forms doubly resolvable row-column designs.
Options
PLOTORDER = string token |
Defines the order in which the plots are formed into replicates (colserpentine, colbycol, rowserpentine, rowbyrow); default rowb |
TIME = scalar |
Time in seconds to spend searching for an optimal design; default 60 |
SEED = scalar |
Seed for the randomization; default 0 |
MAXITERATIONS = scalar |
The number of random designs to search for an optimal design; default 10000 |
Parameters
NROWS = scalars |
Number of rows in the design |
NCOLUMNS = scalars |
Number of columns in the design |
LEVELS = scalar, variate or text |
Defines the number of levels or labels of the TREATMENT factor for each design |
TREATMENTS = factors |
Saves the treatment allocation in each design |
ROWREPLICATES = factors |
Saves the row replicates in each design |
COLREPLICATES = factors |
Saves the column replicates in each design |
ROWS = factors |
Saves the row locations of the plots in each design |
COLUMNS = factors |
Saves the column locations of the plots in each design |
EXIT = scalars |
Saves the exit code from the design search program (0 for success, greater than 0 for failure) |
Description
AGRCRESOLVABLE creates approximately optimal row-column designs. They are formed into replicates in both the row and column directions so that they are doubly resolvable, i.e. resolvable in both row and column directions. The layout of plots must be a complete rectangular array, and the treatments must be equally replicated. This requires that the number of rows multiplied by the number of columns in the array must be equal to the number of treatments multiplied by the number of replicates. The row replicates are comprised of units in adjacent rows, and the column replicates are comprised of units in adjacent columns. This design can be thought of as a generalization of a Latin square, with each treatment occurring once in each row and column replicate.
An example design with four replicates of five treatments in a five-row by four-column array is shown below. As the number of treatments is the same as the number of rows, the column replicates are the same as the columns, so each treatment occurs once in each column. The row replicates are shaded in different colours and consist of five plots from adjacent columns. This is an optimal design, as the treatments in the five rows form a balanced incomplete block design (within the rows, each treatment occurs three times with every other treatment).
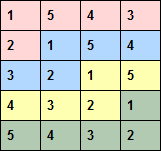
The number of rows and columns in the design must be specified by the NROWS and NCOLUMNS parameters, respectively. The number of treatments is specified by the LEVELS parameter, either as a scalar (defining the number explicitly), or as a variate giving the levels for the treatments, or by a text defining a name for each treatment.
The algorithm has the following constraints. There must be no more than 8000 plots in the design. There must be no more than 4000 rows, columns or treatments. There must be no more than 20 replicates. There must be at least two rows, columns, treatments and replicates. The number of columns must not be greater than the number of treatments. The number of rows can be greater than the number of treatments, but it must be a multiple of the number of treatments (and multiple replicates are then stacked in the columns).
The PLOTORDER option defines the order in which the plots are numbered:
colserpentine |
column-by-column in a serpentine way e.g. top-to-bottom, and then bottom-to-top; |
colbycol |
column-by-column taking the same direction for every column; |
rowserpentine |
row-by-row in a serpentine way e.g. left-to-right, and then right-to-left; |
rowbyrow |
row-by-row taking the same direction for every row (default). |
The TIME option specifies the maximum time in seconds to spend searching for an optimal design; default 60. For large designs, TIME should be increased. For example, 1000 seconds is recommended for more than 100 treatments, and 4000 seconds for more than 200 treatments.
The SEED parameter specifies the starting seed for the randomization process; the default of zero initializes the seed automatically.
The MAXITERATIONS option sets the maximum number of random starting designs to use in the search; default 10000. The search stops when either the TIME or the MAXITERATIONS limit is reached.
The factors for the resulting design can be saved by the TREATMENTS, ROWREPLICATES, COLREPLICATES, ROWS and COLUMNS parameters.
The EXIT parameter can save a scalar which is set to 0 if the design search has found a valid design, 1 if the design limits have been exceeded, 2 if a design is not possible, 3 if no design has been found, and 9 if not enough memory could be allocated for the design search.
Options: PLOTORDER, TIME, SEED, MAXITERATIONS.
Parameters: NROWS, NCOLUMNS, LEVELS, TREATMENTS, ROWREPLICATES, COLREPLICATES, ROWS, COLUMNS, EXIT.
Method
The treatments are allocated in a random order constrained to meet the resolvability criterion, and then the MS criterion (Shah 1960) is optimized by an exchange algorithm. This is repeated until an optimal design is found or the time limit or maximum number of starting designs is reached. The design chosen is one that minimizes the MS criterion.
Reference
Shah, K.R. (1960). Optimality criteria for incomplete block designs. Annals of Mathematical Statistics, 22, 235-247.
See also
Procedure: AFRCRESOLVABLE.
Commands for: Design of experiments.
Example
CAPTION 'AGRCRESOLVABLE Examples'; STYLE=meta
"Simple design of 5 treatments in 5 rows by 4 columns (gives a Youden square)"
AGRCRESOLVABLE [SEED=2637] NROWS=5; NCOLUMNS=4; LEVELS=5; TREAT=Treat; \
ROWS=Row; COLUMNS=Column
FOR
CAPTION 'Treatment layout'; STYLE=minor
TABULATE [CLASS=Row,Column; PRINT=*] !(#Treat); MEANS=tr
PRINT [RLWIDTH=4; IPRINT=*] tr; DECIMALS=0; FIELD=4
CAPTION 'Design efficiency'; STYLE=minor
AEFFICIENCY [FORCED=Row+Column] Treat; EFFICIENCY=ef
CALCULATE meanef = 1/MEAN(1/ef)
& minef = MIN(ef)
& maxef = MAX(ef)
TXCONSTRUCT [TEXT=Efficiency] \
'Efficiency: mean ',meanef,'; range ',minef,' - ',maxef;\
DECIMALS=4
PRINT [IPRINT=*] Efficiency; JUST=left; SKIP=4
ENDFOR
"15 Genotypes x 4 replicates in 10 x 6 array"
TEXT [VALUES='AB14.33','AB15.1','AB15.32','AB18.1','AB19.2','AB19.27', \
'AB21.3','AB21.7','AB25.9','AB27.1','AB27.3','AB27.7','AB31.9',\
'AB31.11','AB32.4'] Gtype
AGRCRESOLVABLE [PLOTORDER=rowserpent; SEED=12457] \
NROWS=10; NCOLUMN=6; LEVELS=Gtype; TREATMENTS=Genotype; \
ROWREPLICATES=RowRep; COLREPLICATES=ColRep; ROWS=Row; COLUMNS=Column
FOR
CAPTION 'Treatment layout'; STYLE=minor
TABULATE [CLASS=Row,Column; PRINT=*] !(#Genotype); MEANS=tr
PRINT [RLWIDTH=4; IPRINT=*; SQUASH=yes] tr; DECIMALS=0; FIELD=4
CAPTION 'Row replicates'; STYLE=minor
TABULATE [CLASS=Row,Column; PRINT=*] !(#RowRep); MEANS=rr
PRINT [RLWIDTH=4; IPRINT=*; SQUASH=yes] rr; DECI=0; FIELD=4
CAPTION 'Column replicates'; STYLE=minor
TABULATE [CLASS=Row,Column; PRINT=*] !(#ColRep); MEANS=cr
PRINT [RLWIDTH=4; IPRINT=*; SQUASH=yes] cr; DECIMALS=0; FIELD=4
CAPTION 'Design efficiency'; STYLE=minor
AEFFICIENCY [FORCED=RowRep/Row+ColRep/Column] Genotype; EFFICIENCY=ef
CALCULATE meanef = 1/MEAN(1/ef)
& minef = MIN(ef)
& maxef = MAX(ef)
TXCONSTRUCT [TEXT=Efficiency] \
'Efficiency: mean ',meanef,'; range ',minef,' - ',maxef;\
DECIMALS=4
PRINT [IPRINT=*] Efficiency; JUST=left; SKIP=4
ENDFOR
"16 cultivars in a 8 x 8 array (pairs of rows & columns make replicates)"
TEXT [VALUES='Apollo','Bumper','Chronicle','Diamond','Earner','Fleet',\
'Golden','Hunter','Inferno','Jimpy','Karamu','Kingdom','Magnum',\
'Orator','Phoenix','Queen'] Names
AGRCRESOLVABLE [PLOTORDER=colserpentine; SEED=75421; MAXITERATIONS=20000] \
NROWS=8; NCOLUMNS=8; LEVELS=Names; TREATMENTS=Cultivar; \
ROWREPLICATES=RowRep; COLREPLICATES=ColRep; ROWS=Row; COLUMNS=Column
FOR
CAPTION 'Treatment layout'; STYLE=minor
TABULATE [CLASS=Row,Column; PRINT=*] !(#Cultivar); MEANS=tr
PRINT [RLWIDTH=4; IPRINT=*] tr; DECIMALS=0; FIELD=4
CAPTION 'Row replicates'; STYLE=minor
TABULATE [CLASS=Row,Column; PRINT=*] !(#RowRep); MEANS=rr
PRINT [RLWIDTH=4; IPRINT=*; SQUASH=yes] rr; DECI=0; FIELD=4
CAPTION 'Column replicates'; STYLE=minor
TABULATE [CLASS=Row,Column; PRINT=*] !(#ColRep); MEANS=cr
PRINT [RLWIDTH=4; IPRINT=*; SQUASH=yes] cr; DECIMALS=0; FIELD=4
CAPTION 'Design efficiency'; STYLE=minor
AEFFICIENCY [FORCED=RowRep/Row+ColRep/Column] Cultivar; EFFICIENCY=ef
CALCULATE meanef = 1/MEAN(1/ef)
& minef = MIN(ef)
& maxef = MAX(ef)
TXCONSTRUCT [TEXT=Efficiency] \
'Efficiency: mean ',meanef,'; range ',minef,' - ',maxef;\
DECIMALS=4
PRINT [IPRINT=*] Efficiency; JUST=left; SKIP=4
ENDFOR
"Create dummy data"
CALC [SEED=573] Yield = NEWLEVELS(RowRep;CUMULATE(GRNORMAL(4;0;1.0))) + \
NEWLEVELS(ColRep;CUMULATE(GRNORMAL(4;0;1.0))) + \
NEWLEVELS(Row;CUMULATE(GRNORMAL(8;0;1.0))) + \
NEWLEVELS(Column;GRNORMAL(8;0;0.5)) + GRNORMAL(64;10;1)
"Analyse dummy data by ANOVA removing both rows and column replicates effects
as in this design these are both orthogonal to treatments as they are
comprised of full rows and columns - however most designs are not orthogoanal"
BLOCKS RowRep + ColRep
TREAT Cultivar
ANOVA [FPROB=yes] Yield
"Analyse data by automatic REML"
VAROWCOLUMN [PBEST=model,means,components; FIXED=Cultivar; RANDOM=ColRep; \
REPLICATES=RowRep; ROWS=Row; COLUMNS=Column; VCONSTRAINTS=positive; \
RSTRATEGY=optimal] Yield