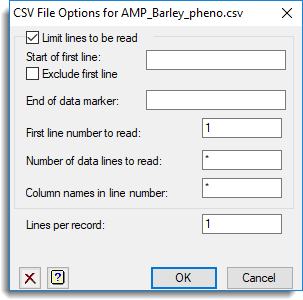
This dialog can be used when importing a CSV file into a spreadsheet to only import part of the file. For example, this could be to import a subset of the lines of data, or to skip the heading and footnote text. These options can also be used to import from files that contain multiple data sections where there are tags to indicate the start and end of a data section.
Limit lines to be read
This option must be selected to use the following options to read just part of the CSV file. The options are kept from the previous usages of this menu, so that turning this off allows previous settings to be retained, but not used for this particular CSV file.
Start of first line
This specifies a text string that specifies the first line. This may be a tag which indicates the start of the data section, or the first column name.
Exclude first line
If the first line is a tag and not part of the data, or the row of column names then you will want to select this item to exclude in from being read as part of the spreadsheet data.
End of data marker
This specifies a text string that specifies the line following the last data line. The line starting with this text will not be read as part of the data, and the previous line will be the last line in the data.
First line number to read
This specifies the first line to start reading the file from. If the Start of first line string is set, it will be looked for after this line, otherwise this line will be the first line read as either column names or data.
Number of data lines to read
This sets the maximum number of data lines to be read in. This can be used to read in just a subset of the data lines.
Column names in line number
By default, if column names are being read in, they will be taken as the first line of the file read (which will depend on the settings of Start of first line or First line number to read settings. Setting this option allows the column names to be read from any line within the CSV file.
Lines per record
N lines in the file will be read as one record. This sometimes happened when lines are wrapped due to a maximum file width, or else if there is some other logic to splitting the data onto multiple lines. The below data format has two lines record.
‘2018-10-11’, 7,
20, 29, 30, 42, 57, 212, 367
‘2018-10-12’, 4,
19, 78, 99, 178
‘2018-10-13’, 5,
9, 23, 45, 87, 132
Each record has a date and count, and then the following line has the items (x count).The setting lines per record to 2 then treats this as:
‘2018-10-11’, 7, 20, 29, 30, 42, 57, 212, 367
‘2018-10-12’, 4, 19, 78, 99, 178
‘2018-10-13’, 5, 9, 23, 45, 87, 132
Action Icons
| Clear | Clear all fields and list boxes. | |
| Help | Open the Help topic for this dialog. |
See also
New Spreadsheet from Clipboard
File New – Spreadsheet
Spreadsheet New Menu
Spreadsheet Add Data Menu
CSV Options when saving to a CSV file