This menu controls aspects of the way in which the clustering is carried out in a non-hierarchical cluster analysis, and selects the information to be printed.
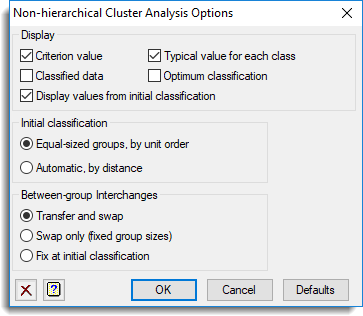
Display
Specifies what is printed during the cluster analysis.
| Criterion value | Optimal criterion value |
| Classified data | Data with the units ordered into the optimal classes |
| Typical value for each class | Displays a typical value for each class: for maximal predictive classification this is the class predictor; for the other methods it is the class mean. |
| Optimum classification | The optimum classification |
If Display values from initial classification is selected, the requested sections of output are also displayed for the initial classification.
Initial classification
This lets you select how the initial classification is formed. Equal-sized groups by unit order splits the units, in order, into k groups of nearly equal size. Automatic, by Distance finds the k units that are furthest apart in the multi-dimensional space defined by the data variates; these are then used as nuclei for the classes, with each remaining unit being allocated to the class containing the nearest nucleus.
Between-group Interchanges
This specifies which types of interchange are to be used to optimize the classification: both transfers and swaps, only swaps, or whether the clusters are to be fixed at those given by the initial classification.
Action Icons
| Clear | Clear all fields and list boxes. | |
| Help | Open the Help topic for this dialog. |
See also
- Non-hierarchical Cluster Analysis menu
- Saving Results for further analysis
- Hierarchical Cluster Analysis
- Principal Components Clustering menu
- CLUSTER procedure