Select menu: Spread | Restrict/Filter | Duplicate Rows
Use this to apply a filter/restriction to the spreadsheet, based on rows which have more than one occurrence of specified values.
- From the menu select Spread | Restrict/Filter | Duplicate Rows.
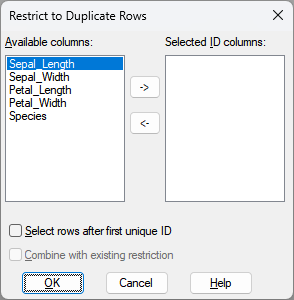
The spreadsheet will be sorted into the order of the Selected ID columns (see below). The rows which have duplicate IDs in the spreadsheet will then be the only rows displayed. This filter will replace any other existing filters on the spreadsheet. An option allows the second and subsequent occurrences to be selected so that these could be copied or deleted to reduce the spreadsheet to having only one occurrence of each ID.
Available columns
This lists all the columns within the spreadsheet. Select the columns that define the row IDs. Use the ![]() button to transfer these into the list of Selected ID columns, or double-click items in this list to transfer them to the Selected ID columns list.
button to transfer these into the list of Selected ID columns, or double-click items in this list to transfer them to the Selected ID columns list.
Selected ID columns
This lists the columns within the spreadsheet whose combination of values define the row IDs. Use the ![]() button to remove columns that have been selected from this list of columns, or double-click the entries to remove them.
button to remove columns that have been selected from this list of columns, or double-click the entries to remove them.
Select rows after first unique ID
If selected, the second and subsequent rows of each duplicated ID will be selected. This will allow an operation such as Spread | Delete | Selected Rows to be used to remove these rows, leaving a single copy of each ID in the spreadsheet.
See also
- Spreadsheet Restrict/Filter Menu for other methods of defining restrictions.
- Restrict Units by Value
- Restrict using Factor Levels
- Restrict using Expression
- Restrict/Filter Random Rows
- Save Restriction/Filter
- Understanding Factors within a Spreadsheet
- Spreadsheet Restrict/Filter Menu
- Spreadsheet Delete Menu for deleting selected rows.
The RESTRICT directive can be used to filter columns within the command language.