This a dialog allow you to save results for the K Nearest Neighbours menu. After selecting the appropriate boxes, you need to type the names for the identifiers of the data structures into the corresponding In: fields.
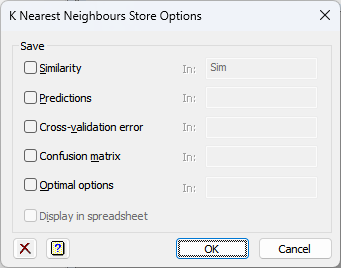
Save
The available save options for are as follows:
| Similarity | Symmetric matrix | The symmetric matrix of similarities between observations. This may be very large. |
| Predictions | Factor or variate | The predicted values for the observations from the rest of the observation using the optimal combination of options. The output type will be the same as the Data to predict structure. |
| Cross-validation error | Scalar | The minimum cross-validation error for the optimal combination of options. If the Data to predict is a factor, this is a mean squared error. If is a factor, it is the percentage of observations for which the predictions and observed values do not match. |
| Confusion matrix | Matrix | The cross tabulation of the observations by the true and predicted groups as a percentage of the true groups for the optimal combination of options. |
| Optimal options | Pointer | A pointer to 3 scalars giving the optimal combination of Minimum similarity Minimum neighbours and Maximum neighbours respectively. |
Display in spreadsheet
Select this to display the results in a new spreadsheet window.
Action Icons
| Clear | Clear all fields and list boxes. | |
| Help | Open the Help topic for this dialog. |
See also
- K Nearest Neighbours menu.
- K Nearest Neighbours Options dialog.
- K Nearest Neighbours Predictions dialog.
- Form similarity matrix menu.
- Canonical variates analysis menu.
- Stepwise Discriminant Analysis menu.
- Classification Trees menu.
- Regression Trees menu.
- Random Classification Forest menu.
- Random Regression Forest menu.
- Multivariate Analysis of Distance menu.
- Hierarchical Cluster Analysis menu.
- KNNTRAIN procedure.
- KNEARESTNEIGHBOURS procedure.
- FSIMILARITY directive for forming similarity matrices.