Selects information to be printed by the analysis and controls certain aspects of the method used.
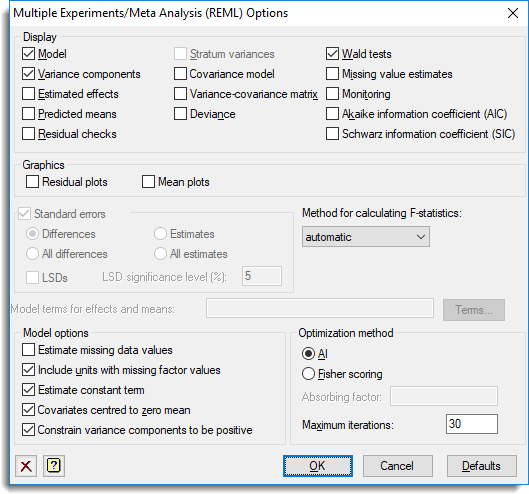
Display
This specifies which items of output are to be produced by the analysis.
| Model | Description of the model fitted by the analysis |
| Variance components | Estimates of variance parameters |
| Estimated effects | Estimates of regression coefficients |
| Predicted means | Predicted means |
| Residual checks | Uses the VCHECK procedure to check the residuals for outliers and variance stability |
| Stratum variances | Estimates of approximate stratum variances |
| Covariance model | Estimated covariance models in matrix format |
| Variance-covariance matrix | Variance-covariance matrix for the variance parameters |
| Deviance | The residual deviance |
| Wald tests | Wald Tests for fixed model terms and accompanying F-statistics (if selected) |
| Missing value estimates | Estimates of values missing from the input |
| Monitoring | Monitoring information at each iteration |
| Akaike information coefficient (AIC) | Akaike information coefficient to assess the random model |
| Schwarz information coefficient (SIC) | Schwarz information coefficient to assess the random model |
Standard errors
Tables of means and effects are accompanied by estimates of standard errors. You can choose whether Genstat computes standard errors or standard errors of differences (SEDs) for the tables. Approximate least significant differences (LSDs) for the predicted means of the fixed terms specified in the Model terms for effects and means field can be computed by selecting LSDs. These are calculated using the approximate numbers of residual degrees of freedom printed by the analysis in the d.d.f column in the table of tests for fixed tests (produced by selecting the Wald tests display option). The degrees of freedom are relevant for assessing the fixed term as a whole, and may vary over the contrasts amongst the means of the term. So the LSDs should be used with caution. If you are interested in a specific comparison, you should set up a 2-level factor to fit this explicitly in the analysis. The significance level for LSDs can be specified as a percentage (default 5) in the accompanying field.
Method for calculating F-statistics
This controls whether Wald tests for fixed effects are accompanied with approximate F statistics and corresponding numbers of residual degrees of freedom. The computations, using the method devised by Kenward & Roger (1997), can be time consuming with large or complicated models. So, the default setting automatic, can be used to allow Genstat to assess the model itself and decide automatically whether to do the computations and which method to use. The other settings allow you to control what to do yourself:
| none | No F statistics are produced |
| algebraic | F statistics are calculated using algebraic derivatives (which may involve large matrix calculations) |
| numerical | F statistics are calculated using numerical derivatives (which require an extra evaluation of the mixed model equations for every variance parameter). |
Model terms for effects and means
This specifies the model terms, as a formula, for which tables of means and/or effects are displayed. For covariates, the associated linear regression parameter can be printed as an effect, but predicted means are not available. Predicted means for other terms are adjusted to the mean of the covariate (but see note below). The formula can include the string ‘Constant’ to include entries for the constant term.
If no formula is specified, means or effects are produced for all the fixed model terms and none of the random terms.
Estimate missing data values
This specifies whether predictions are formed from the fitted model for missing values of the y-variate; alternatively any units with missing values in the y-variate are excluded from the analysis.
Include units with missing factor values
This specifies whether data units with missing values in any of the factors in the fixed or random models are included in the analysis. Units with missing y values are always excluded from the analysis.
Estimate constant term
Specifies whether a constant term is included in the fixed model.
Covariates centred to zero mean
Specifies whether covariates are centred to zero mean during the analysis. This applies to all covariates in the model. If covariates are centred, tables of predicted means are based on the mean covariate value, otherwise zero for each covariate.
Optimization method
The AI (Average information) method is the standard optimization method for REML in Genstat. It uses sparse matrices and is particularly recommended for large datasets and/or complex models. An alternative method is Fisher scoring which, if selected, also allows an absorbing factor to be specified in the model. This can be used to reduce the time or space requirements when fitting large models with many parameters. A more detailed discussion of the use and choice of absorbing factors can be found in the Genstat Reference Manual which is available from the menu by selecting Help | Reference Manual | Directives.
See also
- Multiple Experiments/Meta Analysis (REML) menu.
- REML Meta Analysis Terms for specifying residual terms for the different experiments.
- Linear Mixed Model Further Output for additional output after fitting a model.
- Linear Mixed Models Save for saving the results from a REML analysis.
- VRESIDUAL command for defining residual terms for experiments.
- REML directive for command mode use of REML, with additional options to control the algorithm and for more sophisticated analyses.
- Reml Predictions menu for forming predictions.
- VCHECK procedure to check the residuals.