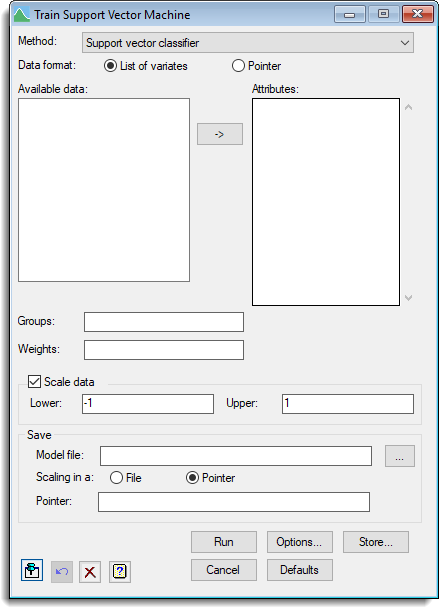
Select menu: Stats | Data Mining | Support Vector Machine | Train
This menu trains or fits a support vector machine, where the membership of groups or the values in the y-variate are explained by a relationship with the attributes using the SVMFIT procedure. The support vector machine uses the attributes to divide the space into regions with their boundaries defined by the support vectors.
- After you have imported your data, from the menu select
Stats | Data Mining | Support Vector Machine | Train. - Fill in the fields as required then click Run.
You can select a range of methods for support vector machines and set or estimate their parameters by clicking Options. You can also store the results by clicking Store.
Method
The method used will be to fit the support vector machine:
| Support vector classifier | The standard support vector machine with a range of kernels for discriminating between groups |
| Nu support vector classifier | A support vector machine with a range of kernels for discriminating between groups with a parameter nu that controls the fraction of support vectors used |
| Support vector regression | The standard support vector machine with a range of kernels for predicting the values of a y-variate as in a regression |
| Nu support vector regression | A support vector machine with a range of kernels for predicting the values of a y-variate as in a regression with a parameter nu that controls the fraction of support vectors used |
| Regularized linear support vector classifier | The standard support vector machine with a linear kernel for discriminating between groups. This is much faster than having the flexibility of choosing the kernel. This method has regularization and algorithmic options to improve its speed, depending on the number of attributes and cases |
| Regularized linear support vector regression | The standard support vector machine with a linear kernel for predicting the values of a y-variate as in a regression. This is much faster than having the flexibility of choosing the kernel. This method has regularization and algorithmic options to improve its speed, depending on the number of attributes and cases |
| Cramer & Singer linear support vector classifier | A support vector machine with a linear kernel for discriminating between groups using the approach of Cramer & Singer, where a direct method for training multi-class predictors is used, rather than dividing the multi-class classification into a set of binary classifications. |
| Consistent support vector classifier | A support vector machine which attempts to identify a consistent group of observations. No Groups or Weights can be set when this method is chosen. |
Data format
How the Attributes will be specified:
| List of variates | A list of variates will be specified. A list box will be displayed into which the names of multiple variates can be entered. The Available data list will display variates of the same length as the Groups field. Use the |
| Pointer | A pointer to a list of variates will be specified. A list of pointers will be displayed in the Available data list. |
Available data
This lists data structures appropriate to the current input field. It lists either factors for specifying the groups, or variates for specifying the data. The contents will change as you move from one field to the next. Double-click on a name to copy it to the current input field or type the name. You can transfer multiple selections from Available data by holding the Ctrl key on your keyboard while selecting items, then click ![]() to move them all across in one action, otherwise the first selected item is added to the current input field.
to move them all across in one action, otherwise the first selected item is added to the current input field.
Attributes
A list of variates or a pointer to a set of variates which will be as the attributes used to explain the membership of Groups or the variation in the Y-variate.
Groups
A factor or a variate specifying the groups for classification.
Y-variate
A factor or a variate specifying the y-variate for a regression.
Weights
A prior weight for each group. This is either the name of a variate, or a space or comma separated list of numbers. The length of the variate or list must match the number of classes in Groups. A larger prior for a class increases the probability of allocating an individual to that class. If this is left empty, all groups have equal priors.
Scale data
If this is selected, the Lower and Upper limits are provided as a either a scalar for a common scaling over all Attributes or as variate with a value for each attribute. A number or the name of a scalar can be entered, or else a variate or space or comma separated list of numbers. If a common scaling is not used, length of the variate or list must match the number of items in the Attributes. If the Lower and Upper limits are not specified, then default values of -1 and 1 will be used for these respectively.
Save
If you wish to use the fitted support vector machine to predict for other observations, you should save the model and any scaling used with the data. The Model file provides a space for a filename to save the model fitted and this can be set with the browse button ![]() . The resulting scaling used for the each attribute can be saved in a File or Pointer depending on the Scaling format that is set. If saving the scaling in a file, this can be set with the browse button
. The resulting scaling used for the each attribute can be saved in a File or Pointer depending on the Scaling format that is set. If saving the scaling in a file, this can be set with the browse button ![]() . The scaling is required when using the Predict menu, but the model file can be left blank, in which case the Predict menu will use the last model fitted by training menu.
. The scaling is required when using the Predict menu, but the model file can be left blank, in which case the Predict menu will use the last model fitted by training menu.
Action Icons
| Pin | Controls whether to keep the dialog open when you click Run. When the pin is down |
|
| Restore | Restore names into edit fields and default settings. | |
| Clear | Clear all fields and list boxes. | |
| Help | Open the Help topic for this dialog. |
See also
- Options for choosing which results to display
- Save options for choosing which results to save
- Predict from Support Vector Machine for predicting from the fitted support vector machine
- Discriminant analysis menu
- SVMFIT procedure
- SVMPREDICT procedure