Select menu: Stats | Data Mining | Neural Network
This menu fits a neural network, where the variation in the y-variate is explained by a non-linear relationship with the x-variates using the NNFIT directive. The type of neural network fitted is a fully-connected feed-forward multi-layer perceptron with a single hidden layer. This network starts with a row of nodes, one for each input variable (i.e. x-variate), which are all connected to every node in the hidden layer. The nodes in the hidden layer are then all connected to the output node in the final, output layer.
- After you have imported your data, from the menu select
Stats | Data Mining | Neural Network. - Fill in the fields as required then click Run.
You can set the number of nodes in hidden layers and types of functions used by clicking Options. You can also store the results by clicking Store.
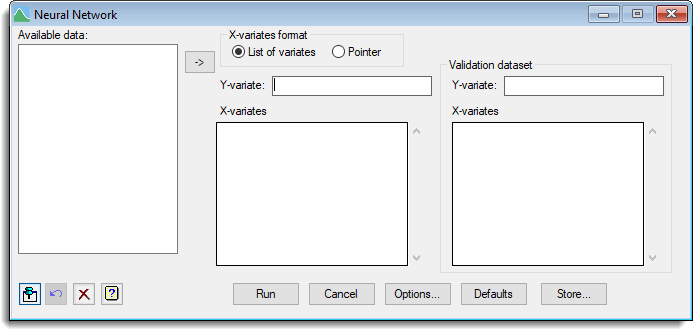
Available data
This lists data structures appropriate to the current input field. It lists either factors for specifying the groups, or variates or pointers for specifying the data. The contents will change as you move from one field to the next. Double-click on a name to copy it to the current input field or type the name. The ![]() button allows multiple selections to be copied from Available data to the X-variates list, otherwise the first selected item is added to the current input field.
button allows multiple selections to be copied from Available data to the X-variates list, otherwise the first selected item is added to the current input field.
X-variates format
How the X-variates will be specified for the training and validation datasets:
| List of variates | A list of variates will be specified. A list box will be displayed into which the names of multiple variates can be entered. The Available data list will display variates of the same length as the Y-variate field. Use the |
| Pointer | A pointer to a list of variates will be specified. A list of pointers will be displayed in the Available data list. |
Y-variate
A variate specifying the response to be explained.
X-variates
A list of variates or a pointer to a set of variates which will be used to explain the variation in the y-variate.
Validation dataset
A second dataset can be used for validation of the neural network. The optimization of the network tends to over-fit the model, but using a separate dataset to the training dataset gives an independent measure of how well the network may perform. For example you could split the full data set into training and validation datasets for this purpose. The validation data set must have fewer observations than the training dataset. Specifying a validation dataset is optional. If specified, both the Y-variate and X-variates must be provided.
Validation Y-variate
A variate specifying the response for the validation set.
Validation X-variates
A list of variates or a pointer to a set of variates which will be used to independently measure the variation explained by the model. This list or pointer must have the same number of elements as the X-variates item.
Action Icons
| Pin | Controls whether to keep the dialog open when you click Run. When the pin is down |
|
| Restore | Restore names into edit fields and default settings. | |
| Clear | Clear all fields and list boxes. | |
| Help | Open the Help topic for this dialog. |
See also
- Options for choosing which results to display
- Store options for choosing which results to save
- Discriminant analysis menu
- Stepwise discriminant analysis menu
- NNFIT directive