Select menu: Stats | Multivariate Analysis | Stepwise Discriminant Analysis
This dialog performs stepwise discriminant analysis.
- After you have imported your data, from the menu select
Stats | Multivariate Analysis | Stepwise Discriminant Analysis.
OR
Stats | Data Mining | Stepwise Discriminant Analysis. - Fill in the fields as required then click Run.
You can set additional Options before running and store the results by clicking Store.
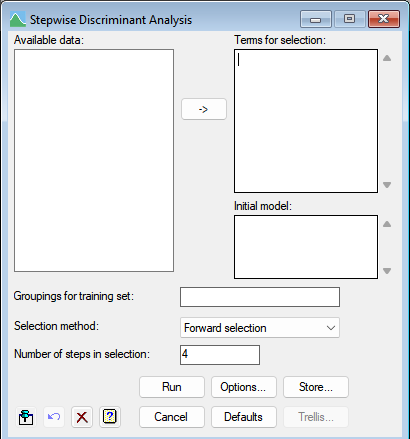
The data for the dialog is given by a set of variates defining the attributes of the units and a factor specifying the pre-defined groupings of the units from which the allocation is derived (the ‘training set’). An initial starting model (if any) of a set of variates is defined in the Initial model field and then a set of variates that could be selected for the model is specified in the Terms for selection field.
The stepwise algorithm works either from the initial model adding in the best variate at each step (Forward selection), or from the full model with all initial and potential variates, dropping the worst variate at each step (Backward elimination).
The criteria for the best model is set in the Options dialog. Any unit with a missing value in any of the variates is excluded from the analysis. Note: The levels of the grouping factor must all exceed -9999, or a mis-allocation of the units may result.
Available data
This lists data structures appropriate to the current input field. It lists either factors for specifying the groups, or variates for specifying the data. The contents will change as you move from one field to the next. Double-click on a name to copy it to the current input field or type the name.
Terms for selection
Used to enter the names of the potential variates defining the attributes of the units. The variates from the final model will be selected from this list. You can transfer multiple selections from Available data by holding the Ctrl key on your keyboard while selecting items, then click ![]() to move them all across in one action.
to move them all across in one action.
Initial model
Used to enter the names of the variates defining the attributes of the units that must be in the model. The final model will always contains these variates. You can transfer multiple selections from Available data by holding the Ctrl key on your keyboard while selecting items, then click ![]() to move them all across in one action.
to move them all across in one action.
Groupings for each training set
A factor specifying the pre-defined groupings of the units for the training set.
Selection method
The stepwise algorithm to use for selecting the variates to be used in the discriminant model.
| Forward selection | Works either from the initial model adding in the best variate at each step |
| Backward elimination | Work from the full model dropping the worst variate at each step |
Action buttons
| Run | Run the analysis. |
| Cancel | Close the menu without further changes. |
| Options | Opens a dialog where additional options and settings can be specified for the analysis. |
| Defaults | Set the menu settings back to the default settings. Clicking the right mouse on this button produces a pop-up menu where you can choose to set the options using the currently stored defaults or the Genstat default settings. |
| Save | Opens a dialog to specify names of structures to save the results from the analysis. |
| Trellis plot | Open the dialog which creates a 2d-trellis plot of groups. |
Action Icons
| Pin | Controls whether to keep the dialog open when you click Run. When the pin is down |
|
| Restore | Restore names into edit fields and default settings. | |
| Clear | Clear all fields and list boxes. | |
| Help | Open the Help topic for this dialog. |
See also
- Options for choosing which results to display
- Save options for choosing which results to save
- Discriminant analysis menu
- Canonical variates analysis menu
- K Nearest Neighbours menu
- Regression Trees menu
- Random Regression Forest menu
- Classification Trees menu
- Random Classification Forest menu.
- SDISCRIMINATE procedure
- DISCRIMINATE procedure
- CVA directive